The way a completed translation has been produced has changed markedly over the decades since my first days as a translator for Imperial Tobacco in Bedminster, Bristol.
In those days I’d write out the translation in longhand from printed source material and take my manuscript to the typing pool where it would be transformed into typescript.
The next big change came with my learning how to touch-type. By this time I was a freelance with no more access to a typing pool.
In my early freelance days, it was rare to get editable copy that one could overkey with one’s usual word processor, spreadsheet or presentation package. The standard way of working was still from hard copy propped up in a copyholder alongside one’s keyboard.
Then there came a large surge in the use of formats such as PDF – Portable Document Format. This format enables documents, including text formatting and images, to be presented in a manner independent of application software, hardware and operating systems.
If the PDF was text-based, one could simply export the text as plain ASCII text or copy and paste it into a word processor.
However, if I had an image-based PDF to work with, my usual answer was to print it out as hard copy to be propped up in a copyholder alongside my keyboard. This was very expensive in terms of paper and other consumables for the printer, even with a machine as parsimonious as my trusty mono laser printer, whose cartridge was good for printing 3,000 or so pages of copy.
In addition to the expense of printing, there was a far greater drawback to bear in mind, i.e. one could easily miss a sentence or paragraph from the original text when keying in the translated from a hard copy original, with the consequent implications for the quality of the finished work and the client’s satisfaction with it.
Then I discovered OCR – Optical Character Recognition – the mechanical or electronic conversion of images of typed, handwritten or printed text into machine-encoded text.
Here’s a short video explaining the basics of OCR.
My preferred OCR package is gImageReader and – as with the software I recommend for use by translators – is open source and available for both Linux and Windows.
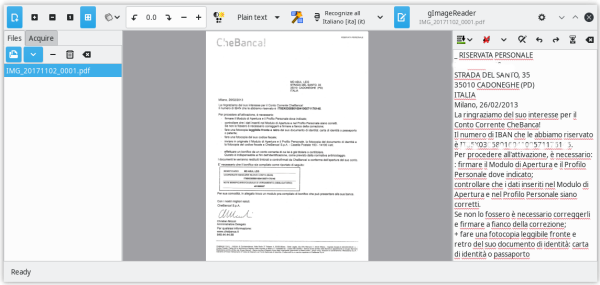
gImageReader provides a simple graphical front-end to the tesseract OCR engine. The features of gImageReader include:
- Importing PDF documents and images from disk, scanning devices, clipboard and screenshots;
- Process multiple images and documents in one go;
- Manual or automatic recognition area definition;
- Recognising to plain text or to hOCR documents;
- Recognized text displayed directly next to the image;
- Post-processing of the recognised text, including spellchecking;
- Generating PDF documents from hOCR documents.
I generally just stick scanning the input file to plain text, which can then be fed into a regular office suite for translation. If your office suite can handle HTML that’s the format gImageReader outputs as its hOCR output.
The tesseract OCR engine mentioned above can also be enhanced with language packs for post-recognition spellchecking, as mentioned in the features above. At present, tesseract can recognise over 100 different languages.
In addition to GUI-based OCR, there are also Linux packages available which can perform OCR via the command line interface.
My tool of choice here is OCRmyPDF.
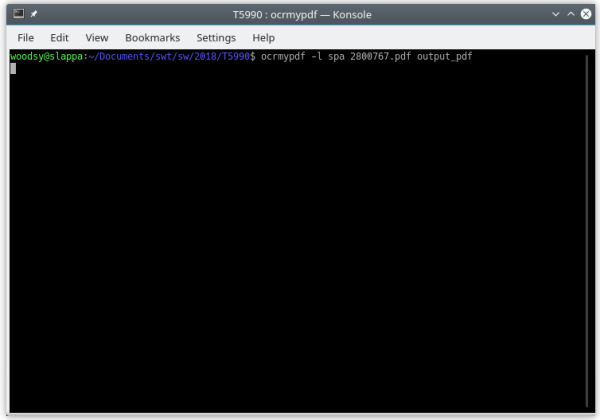
OCRmyPDF is a package written in Python 3 that adds OCR layers to PDFs and, like gImageReader, also uses the tesseract OCR engine.
Using OCRmyPDF on the command line is simplicity itself (as shown in the screenshot above:
ocrmypdf -l [language option] inputfile.pdf outputfile.pdf
More complicated command options are possible, but after using that simple string above, you’ll be able to extract the text from your formerly image-based PDF ready for translation.
By way of conclusion depending on the software itself, OCR packages can also extract text from images such as .jpg files.